
Most scraping failures are predictable once you measure the right things. Marketing and business teams want reliable acquisition from product pages, search results, and reviews, yet too many pipelines rely on trial and error. A practical strategy uses verifiable signals about browsers, networks, and page behavior so you can tune scrapers with confidence, not guesswork.
Account for JavaScript-heavy pages before you write a line of code
Client-side execution is the default on the modern web. Over 97% of websites execute JavaScript on the client, which means raw HTML fetches often miss the actual state of the page. Plan for a real browser context where needed and budget for it. Median desktop pages transfer around 2 MB of data and make roughly 70 or more requests, so concurrency planning must factor bandwidth, CPU for rendering, and third-party calls that you do not control. If you do not track these basics, you will chase red herrings when timeouts climb.

Match the browser your targets expect
Websites tune experiences to mainstream clients. Chrome accounts for roughly two thirds of desktop browsing, so a Chrome-based automation stack with stable, human-like settings reduces anomalies. Keep a consistent user agent family, negotiate HTTP/2 or HTTP/3 where the origin offers it, and reuse session cookies across logical flows. Track acceptance rates for cookies and service workers, and compare time to first byte across a headless and headed profile. If the headed profile consistently yields faster first byte and fewer 403 or 429 responses, the site is fingerprinting aggressively and parity matters more than speed.
Control IP entropy, not just rotation
IP strategy is a math problem as much as it is a sourcing problem. IPv4 provides about 4.29 billion addresses and has been effectively exhausted at regional registries, so many providers recycle ranges that appear frequently in blocklists. At the same time, around 40% of user traffic now supports IPv6, which some targets treat differently from legacy IPv4. Measure blocks by autonomous system number and by country, not just by individual IP, and tune rotation frequency to the target’s session model. Over-rotating can look mechanical, while moderate reuse within a cookie-bound session often reduces challenges. Track success rate deltas when you switch from datacenter to residential pools on ecommerce and ticketing sites; expect meaningful differences because residential paths resemble real consumer traffic patterns.
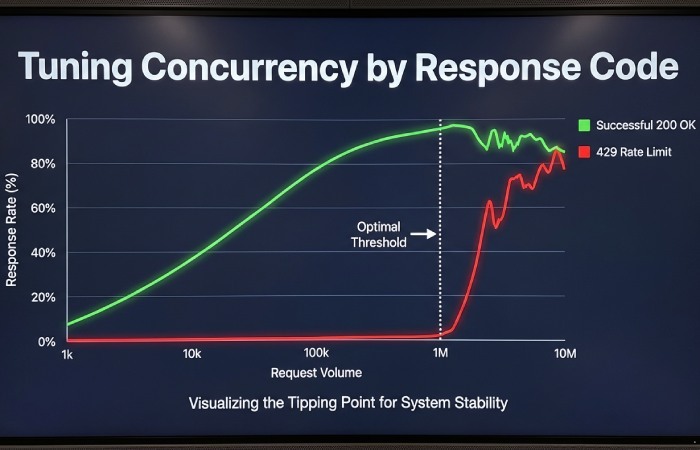
Let the response codes set your concurrency
Concurrency that is safe for a static page can flood a dynamic one. Ramp in small steps and plot the mix of 2xx, 4xx, and 5xx responses. A rising share of 429 means rate limiting, and a rising 403 alongside normal latency often means reputation filtering. Hold the highest concurrency that keeps the 429 share flat and preserves stable latency. Watch the 95th percentile for time to first byte; if it balloons while the average stays flat, you are saturating a bottleneck and should back off before blocks follow.
How to diagnose proxy failures without guesswork
Start with a clean target URL set and test each proxy for DNS resolution time, TLS handshake time, HTTP protocol support, and basic 2xx reachability. Then replay the same request set through your full scraper to compare the delta between transport health and end-to-end success. This isolates whether problems are due to network quality or application fingerprinting. Validate that IPs originate from the regions you intend, and verify that reverse DNS and ASN align with your needs. When you need a quick check on large pools, a purpose-built tool like https://pingproxies.com/proxy-tester helps you remove obviously failing endpoints before they poison your success rate.
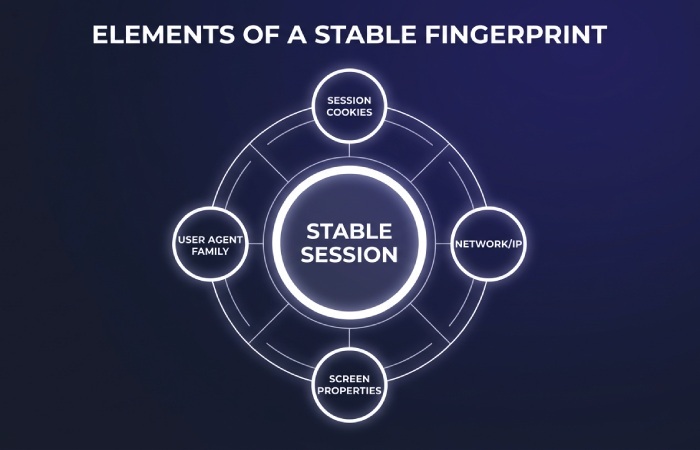
Stabilize sessions and identifiers
Many commercial sites throttle based on identity signals beyond IP. Keep session cookies alive for realistic durations, respect caching headers for static assets, and avoid refetching the same script bundles every visit. Record and replay a stable set of navigator and screen properties across a session to avoid churning fingerprints. Measure block rates when you change only one variable at a time, such as toggling hardware concurrency or WebGL data. Small consistency improvements often move success rates more than adding more IPs.
Acquire only what you can verify
Data that cannot be validated is a liability. For product catalogs, compute inexpensive content hashes from normalized fields to detect duplicates and churn. Maintain a small, fixed control set of URLs for each source and run it on every build to track regressions. Any change in field coverage or character-level similarity on the control set is an early warning that parsing or rendering behavior shifted. Store the raw response alongside parsed output so that marketing and analytics teams can reprocess records when business rules change without hitting the site again.
Respect site rules to protect your pipeline
Compliance is not just legal hygiene; it correlates with stability. Honor robots directives and honor takedown requests promptly. Back off automatically on login walls and gated content that requires user consent. The time saved on firefighting blocks easily exceeds the effort you spend building these checks into your crawler.
Well-run data acquisition is measurable. When you align your browser behavior with what sites expect, treat IPs as structured signals, and let response codes and latency guide concurrency, you trade guesswork for repeatability. That is how scraping becomes a dependable input to software, marketing, and business decisions.
Similarly, in email security, authentication protocols like SPF, DKIM, and DMARC verify senders and protect domains from spoofing and phishing.